mpls vpn技术原理-凯发平台
1 mpls提出的意义
传统的ip数据转发是基于逐跳式的,每个转发数据的路由器都要根据ip包头的目的地址查找路由表来获得下一跳的出口,这是个繁琐又效率低下的工作,主要的原因是两个:1、有些路由的查询必须对路由表进行多次查找,这就是所谓的递归搜索;2、由于路由匹配遵循最长匹配原则,所以迫使几乎所有的路由器的交换引擎必须用软件来实现,用软件实现的交换引擎和atm交换机上用硬件来实现的交换引擎在效率上无法相抗衡。
当今的互联网应用需求日益增多,对带宽、对时延的要求也越来越高。如何提高转发效率,各个路由器生产厂家做了大量的改进工作,如cisco在路由器上提供cef(cisco express forwarding)功能、修改路由表搜索算法等等。但这些修补并不能完全解决目前互联网所面临的问题。
ip和atm曾经是两个互相对立的技术,各个ip设备制造商和atm设备制造商都曾努力想吃掉对方,想ip一统天下,或者atm一家独秀!但是最终是这两种技术的融合,那就是mpls(multi-protocol label switching)技术的诞生!mpls技术结合和ip技术信令简单和atm交换引擎高效的优点!
2 mpls技术的实现细节
2.1 标签结构
ip设备和atm设备厂商实现mpls技术是在各自原来的基础上做的,对于ip设备商,它修改了原来ip包直接封装在二层链路帧中的规范,而是在二层和三层包头之间插了一个标签(label),而atm设备制造商利用了原来atm交换机上的vpi/vci的概念,在使用label来代替了vpi/cvi,当然atm交换机上还必修改信令控制部分,引入了路由协议,atm交换使用了路由协议来和其他设备交换三层的路由信息。
标签的结构如下:

20比特的label字段用来表示标签值,由于标签是定长的,所以对于路由器来说,可以分析定长的标签来做数据包的转发,这是标签交换的最大优点,定长的标签就意味着可以用硬件来实现数据转发,这种硬件转发方式要比必须用软件实现的路由最长匹配转发方式效率要高得多!
3比特的exp用来实现qos
1比特s值用来表示标签栈是否到底了,对于vpn,te等应用将在二层和三层头之间插入两个以上的标签,形成标签栈。
8比特ttl值用来防止数据在网上形成环路。
这样完整的带有标签的二层帧就成了如下形式:
在atm信元模式下,信元的结构如下形式:
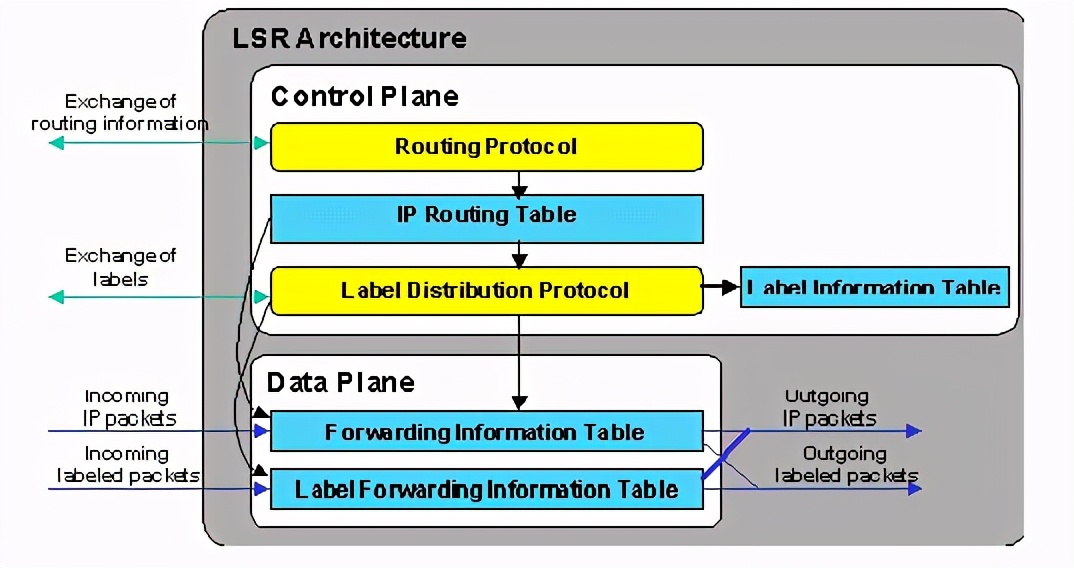
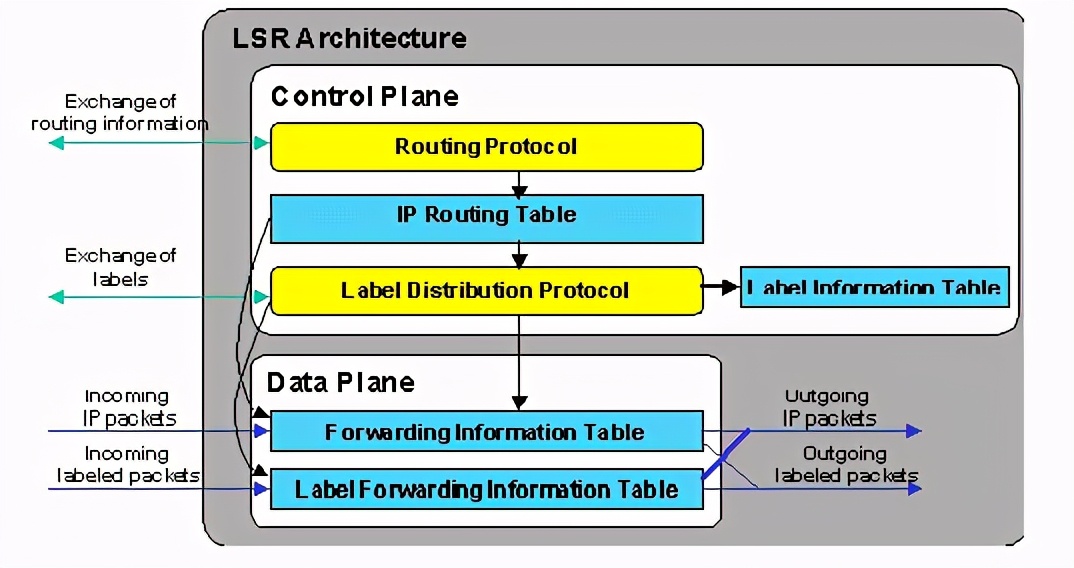
2.2 lsr设备的体系结构
通过修改,能支持标签交换的路由器为lsr(label switch router),而支持mpls功能的atm交换机我们一般称之为atm-lsr。
lsr设备的体系结构如下:
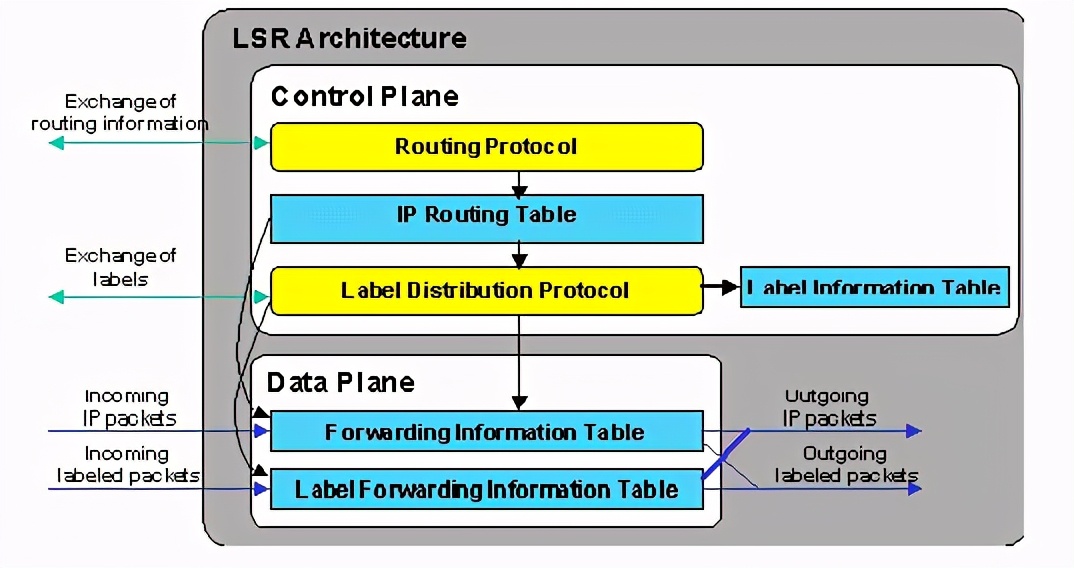
lsr的体系结构分为两块:
1. 控制平面(control plane)
该模块的功能是用来和其他lsr交换三层路由信息,以此建立路由表;和交换标签对路由的绑定信息,以此建label
information table(lib)标签信息表。同时再根据路由表和lib生成forwarding information
table(fib)表和label forwarding information
table(lfib)表。控制平面也就是我们一般所说的路由引擎模块!
2.数据平面(data plane)
数据平面的功能主要是根据控制平面生成的fib表和lfib表转发ip包和标签包。
对于控制平面中所使用的路由协议,可以使用以前的任何一种,如ospf、rip、bgp等等,这些协议的主要功能是和其他设备交换路由信息,生成路由表。这是实现标签交换的基础。在控制平面中导入了一种新的协议—ldp,该协议的功能是用来针对本地路由表中的每个路由条目生成一个本地的标签,由此生成lib表,再把路由条目和本地标签的绑定通告给邻居lsr,同时把邻居lsr告知的路由条目和标签绑定接收下来放到lib表里,最后在网络路由收敛的情况下,参照路由表和lib表的信息生成fib表和lfib表。具体的标签分发模式如下叙述。
2.3 标签的分配和分发
上面叙述到了,mpls技术是ip技术和atm技术的融合。lsr和atm-lsr上实现标签的生成和分发是有点不同的。
2.3.1 包模式(packet mode)下的标签的分配和分发
对于实现包模式mpls网络中,是下游lsr独立生成路由条目和标签的绑定,并且是主动分发出去的。
如上图,所有lsr上启动了ldp协议。以lsr-b为例,它已经通过路由协议获得网络x的路由了,一旦启动ldp协议,lsr-b立即查找路由表,如果x网络的路由是由igp路由协议学到的,则在lib表中为通向x网络的路由生成一个本地标签25,由于lsr-b和lsr-a、lsr-c、lsr-e形成了ldp邻居关系,所以下游lsr-b会主动给所有的邻居发送这个x=25的路由条目和标签的绑定!lsr-a、lsr-e、lsr-c会把该路由条目和标签的绑定放置到本地的lib表中,再结合本地的路由表,在fib表中生成有关x网络的“网络地址->出标签”条目,在lfib中生成有关x网络的“进标签->出标签”条目。所有的lsr上都如此操作。最终的结果使整个mpls网络内部所有lsr上达到路由表、lib表、fib表、lfib表的动态平衡。
如果lsr-a接收到要去x网段的数据,由于lsr-a处在mpls网络的边缘,必须查找fib表,对接收到的ip包,做标签插入操作。对于lsr-b,lsr-c则纯粹是分析标签包,对包头的标签做转换,再转发标签包而已。数据到了lsr-d,该边缘lsr会去掉标签包中的标签,再对恢复的ip包做转发!如下图:
2.3.2
信元模式(cell mode)下的标签分配和分发
在信元模式下,下游atm-lsr接收到了上游atm-lsr标签绑定请求后,下游受控分配标签,被动向上游分发标签。如下图
最上游的lsr-a向atm-lsr-b发起对网络x的标签求情,atm-lsr-b再向atm-lsr-c发请求,最后请求到达lsr-d,lsr-d生成本地对x网络的标签1/37,把该标签告诉atm-lsr-c,c做同样操作,这样一步一步到达lsr-a。最终生成一条从a->b->c->d的lsp(label switch path)。这样如果a收到要到x网络的数据,a就把ip数据包分割成带有标签的信元,通过atm接口发送到b,接下来b和c就纯粹做atm信元的转发,到了d后再把信元组合成ip数据包,发向网络x。
在此要强调的如果要组建以atm交换机为核心的mpls网络,那么在atm网络的边缘必须设置路由器,原因在于atm交换机只转发信元,无法处理用户数据ip包。当然上面也提到要在atm交换机上实现mpls功能,必须在atm交换机的信令控制部分加入路由协议,而路由信息包往往是打在ip包中的,如rip,ospf,bgp等路由协议。atm交换机为了确保这些以ip包形式传递的路由信息能够在atm交换机间传递,使用了专门的带外连接通道或者带内的管理vc。
2.4 bgp协议在mpls网络中的特殊应用
上面提到lsr根据路由表分配标签时,只对从igp协议获得的路由条目分配标签。原因何在?这是有特殊意义的!看下图:
整个transit as中启动mpls交换。保证isp2和lsr-border2之间的网段发布到transit as内部的igp路由协议中,对isp1和lsr-border2之间的网段也做同样的要求。前面提到过lsr为路由条目分配标签时,只对从igp学来的路由分配标签,而网络1.2.3.4是被发布到transit as内部的igp路由协议中了,可以肯定在border1处是可以获得core1告诉它有关1.2.3.4网络的标签23。lsr-border1,lsr-border2之间形成ibgp邻居关系,通过bgp协议,lsr-border2把从isp2处学来的10.0.0.0/8这条路由告诉给lsr-border1,这条路由的下一跳地址是1.2.3.4,这样一来让lsr-border1得知要给网络10.0.0.0/8发送数据,先把数据发送到1.2.3.4这个网络来。1.2.3.4被绑定了标签23,所以在生成fib表时,也给10.0.0.0/8这个网段绑定一个标签23。这样,如果有数据从isp1穿越transit as到达isp2,在border1处就会给ip包插上23这个标签,把生成的标签包转发到core1,core1就只要分析标签头做标签包的转发就可以了!由于transit as内部核心路由器不必要运行bgp协议,这样一来,mpls网络的核心路由器就不会知道外部用户的路由,缩小了核心路由器的路由表,提高了搜索效率。大家也看到,由于打上了标签,ip包头是不会在核心路由器被分析的,即使ip包头含有10.0.0.1这样的私有ip地址,也会因为只分析标签的原因被正常转发,这就是服务提供商提供vpn服务所追求的。当然在此必须重声,lsp在整个transit as不能被断开,如果断开,标签包就恢复成ip包,而核心路由器是不含用户路由的,最终导致数据包的丢失。
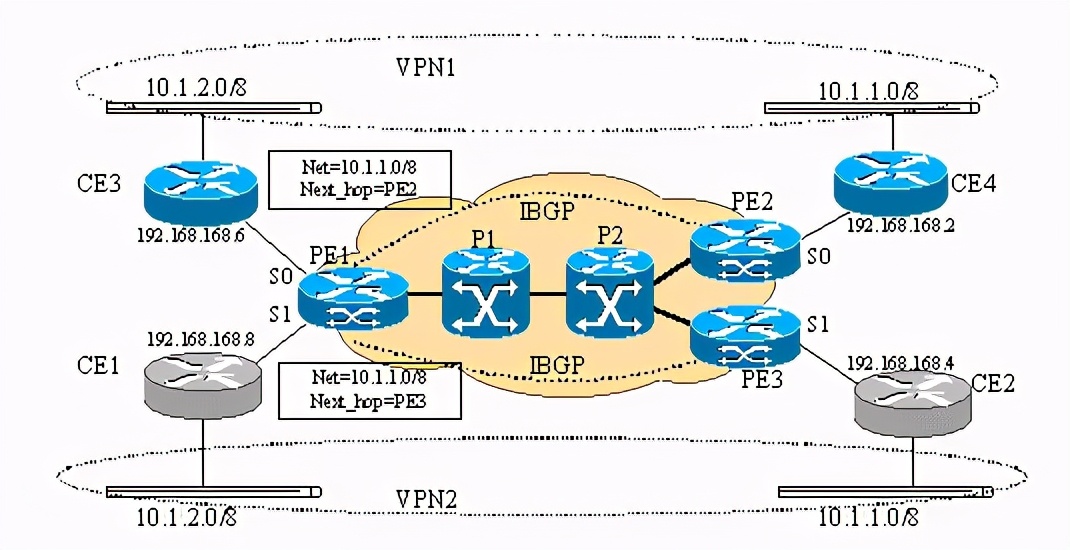
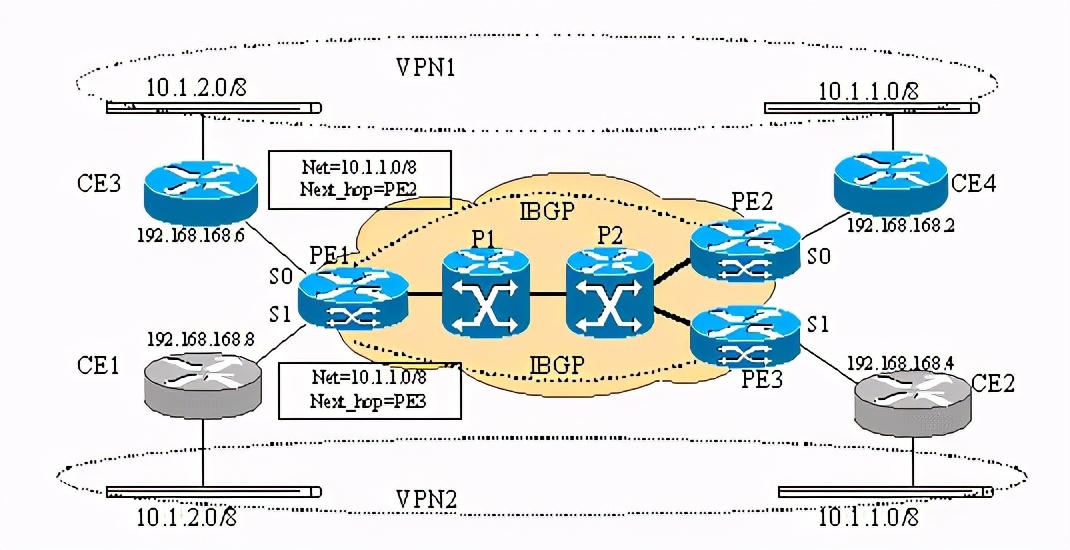
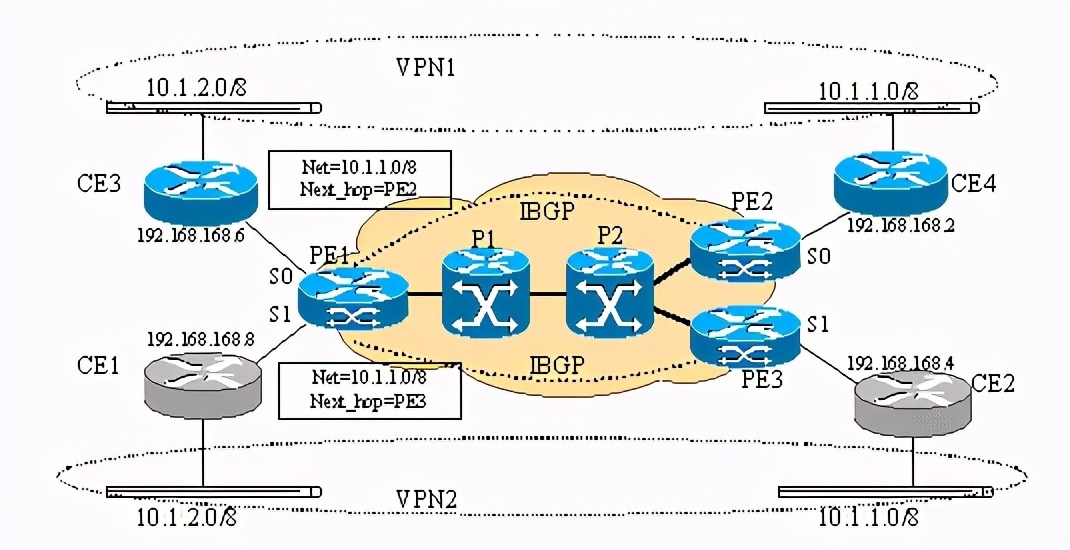
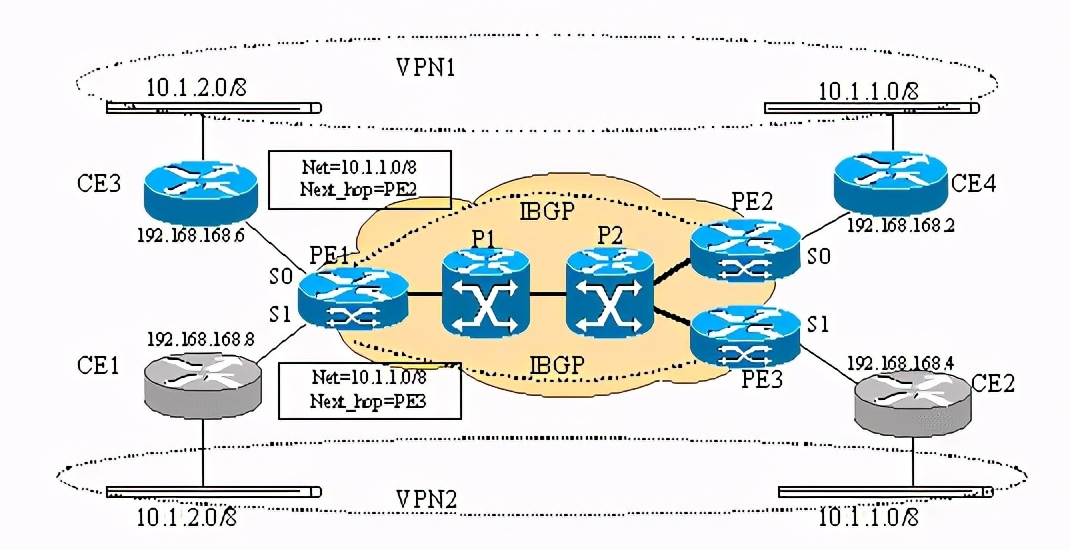
bgp在mpls网络中的作用为我们提供了vpn服务打开了方便之门,但也应该意识到vpn服务两个最基本的要求是1.用户可以独立规划ip地址;2.安全性非常重要!看下图:
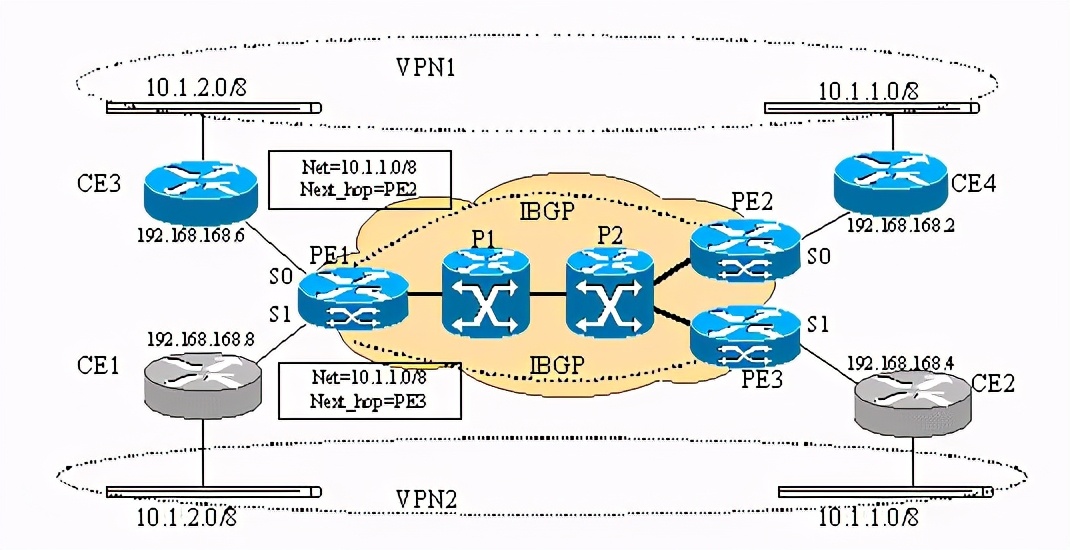
以上为两个vpn实例,pe1(pe=provider edge device)上分别接了ce1 (ce=customer edge device)和ce3,但是ce1和ce3上带到ip地址相同的网 段10.1.2.0/8,很明显如果不对pe1路由器做修改,pe1只能认为往10.1.2.0/8的数据要么从s0出,要么从s1出,这样的话,不是ce1就是ce3就更本收不到从pe1发来的前往10.1.2.0/8网段的数据!
如果不对bgp4协议做修改,那么pe2和pe3发送给的pe1的有关10.1.1.0/8网络的路由更新就有可比性,pe1最终会选择一条路由,认为或是pe2或者pe3是发送数据到10.1.1.0/8的必经路由器。这样如果ce1带的10.1.2.0/8网段上的主机给10.1.1.0/8网段上的主机发送数据时,可能会发到ce4所带的10.1.1.0/8的网段上,这样造成了数据泄露。
所以,为了使lsr能提供基于mpls的vpn服务,还必须对此类设备做修改。
3 基于mpls的vpn实现
3.1 vpn的历史
vpn服务是很早就提出的概念,不过以前电信提供商提供vpn是在传输网上提供的覆盖型的vpn服务。电信运营商给用户出租线路,用户上层使用何种的路由协议、路由怎么走等等,这些电信运营商不管。这种租用线路来搭建vpn的好处是安全,但是价格昂贵,线路资源浪费严重。
后来随着ip网络的全面铺开,电信服务提供商在竞争的压力下,不得不提供更加廉价的vpn服务,也就是三层vpn服务。通过提供给用户一个ip平台,用户通过ip over ip的封装格式在公网上打隧道,同时也提供了加密等等的手段提供安全保障。这类vpn用户在目前的网络上数量还是相当巨大的!但是这类vpn服务因大量的加密工作、传统路由器根据ip包头的目的地址转发效率不高等等的原因不是非常令人满意。
mpls技术的出现和bgp协议的改进,让大家看到了另一种实现vpn的曙光。
3.2 mpls/vpn体系结构
3.2.1 pe路由器的改造和vrf的导入
为了让pe路由器上能区分是哪个本地接口上送来的vpn用户路由,在pe路由器上创建了大量的虚拟路由器,每个虚拟路由器都有各自的路由表和转发表,这些路由表和转发表统称为vrf(vpn routing and forwarding instances)。一个vrf定义了连到pe路由器上的vpn成员。vrf中包含了ip路由表,ip转发表(也称为cef表),使用该cef表的接口集和路由协议参数和路由导入导出规则等等。
在vrf中定义的和vpn业务有关的两个重要参数是rd(route distinguisher)和rt(route target)。rd和rt长度都是64比特。
有了虚拟路由器就能隔离不同vpn用户之间的路由,也能解决不同vpn之间ip地址空间重叠的问题。
3.2.2 mp-bgp协议对vpn用户路由的发布
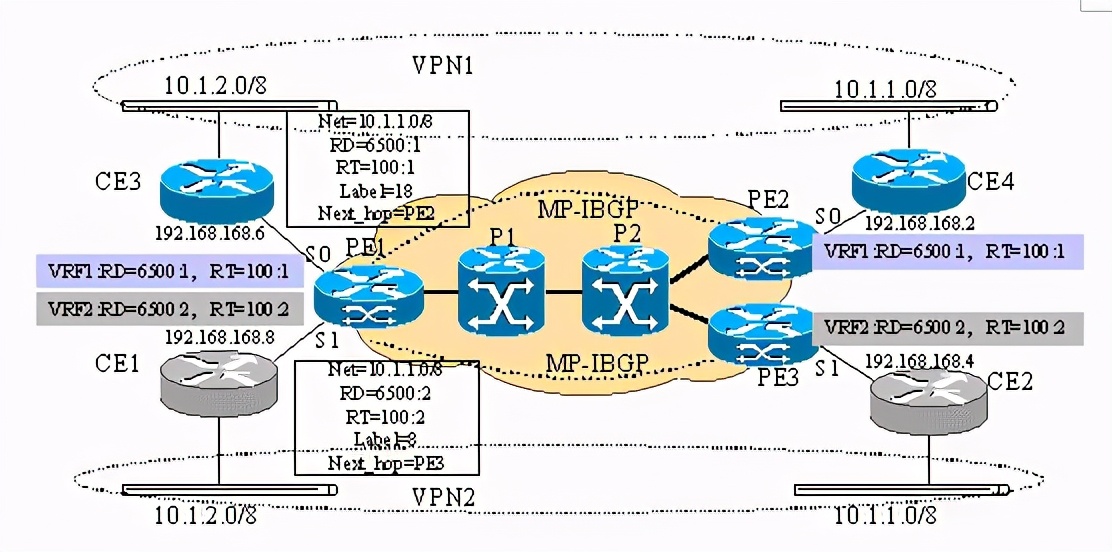
正常的bgp4协议能只传递ipv4的路由,由于不同vpn用户具有地址空间重叠的问题,必须修改bgp协议。bgp最大的优点是扩展性好,可以在原来的基础上再定义新的属性,通过对bgp修改,把bgp4扩展成mp-bgp。在mp-ibgp邻居间传递vpn用户路由时打上rd标记,这样vpn用户传来的ipv4路由转变为vpnv4路由,这样保证vpn用户的路由到了对端的pe上,能够使对端pe区分开地址空间重叠但不同的vpn用户路由。例子如下:
在pe1、pe2、pe3上分别配置vrf参数,其中vpn1用户的rd=6500:1,rt=100:1,vpn2用户的rd=6500:2、rt=100:2。所有vrf可以同时 导入和导出所定义的rt。
以pe2为例,pe2从接口s0上获得由ce4传来的有关10.1.1.0/8的路由,pe2把该路由放置到和s0有关的vrf所管辖的ip路由表中,并且分配该路由的本地标签,注意该标签是本地唯一的。通过路由重新发布把vrf所管辖的ip路由表中的路由重新发布到bgp表中,此时通过参考vrf表的rd、rt参数,把正常的ipv4路由变成vpnv4路由,如10.1.1.0/8变成6500:1:10.1.1.0/8,同时把导出(export)rt值和该路由的本地标签值等等的属性全部加到该路由条目中去。通过mp-ibgp会话,pe2把这条vpnv4路由发送的pe1处,pe1收到了两条有关10.1.1.0/8的路由,其中一条是由pe3发来的,由于rd的不同,导致该两条路由没有可比性。mp-bgp接受到该两条路由后的后继工作是:去掉vpn4路由所带的rd值,使之恢复ipv4路由原貌,并且根据各vrf配置的允许导入(import)的rt值,把ipv4倒到各个vrf管辖的路由表和cef表中,也就是说带有rt=100:1的10.1.1.0/8的路由倒到vrf1所管的路由表和cef表中,带有rt=100:2的10.1.1.0/8的路由倒到vrf2所管辖的路由表和cef表中。再通过ce和pe之间的路由协议,pe把不同的vrf管辖的路由表内容通告的各自的相联的ce中去。
目前pe和ce之间可支持的路由协议只有四种bgp、ospf、rip2或者静态路由。
3.2.3 mpls/vpn中标签分组的转发
通过mp-bgp协议各个vpn用户路由器学习到正确的路由,现在看看如何转发用户数据的。
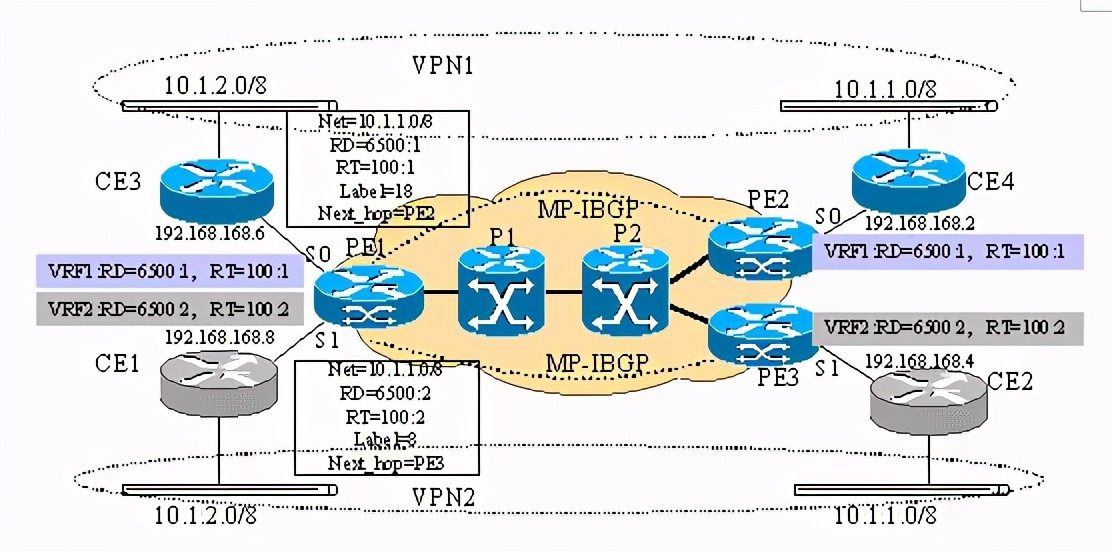
1.ce1接收到发往10.1.1.1的ip数据包,查询路由表,把该ip数据包发送到pe1。
2.pe1从s1口上收到ip数据包后,根据s1所在的vrf,查询对应的cef表,数据包打上标签8,注意该标签就是通过mp-bgp协议传来的。pe1继续查询全局cef表,获知要把数据发往10.1.1.1,必须先发送到pe2,而要发送到pe2,则必须打上由p1告知的标签2。所以该ip包被打上了两个标签。
3.p1接收到标签包后,分析顶层的标签,把顶层标签换成4,继续发送的p2。
4.p2和p1一样做同样的操作,由于次末中继弹出机制,p2去掉标签4,直接把只带有一个标签的标签包发送的pe2。
5.pe2收到标签包后,分析标签头,由于该标签8是它本地产生的,而且是本地唯一的,所以pe2很容易查出带有标签8的标签包应该去掉标签,恢复ip包原貌,从s1端口发出。
6.ce2获得ip数据包后,进行路由查找,把数据发送到10.1.1.0/8网段上。
4 mpls/vpn配置实例
要提供vpn服务的前提是:服务提供商的网络必须启用标签交换功能,即把以前的数据网络升级为mpls网络。然后具体配置pe,pe上的配置按六步走:
1.定义并且配置vrf
2.定义并且配置rd
3.定义rt,并且配置导入导出策略
4.配置mp-bgp协议
5.配置pe到ce的路由协议
6.配置连接ce的接口,将该接口和前面定义的vrf联系起来。
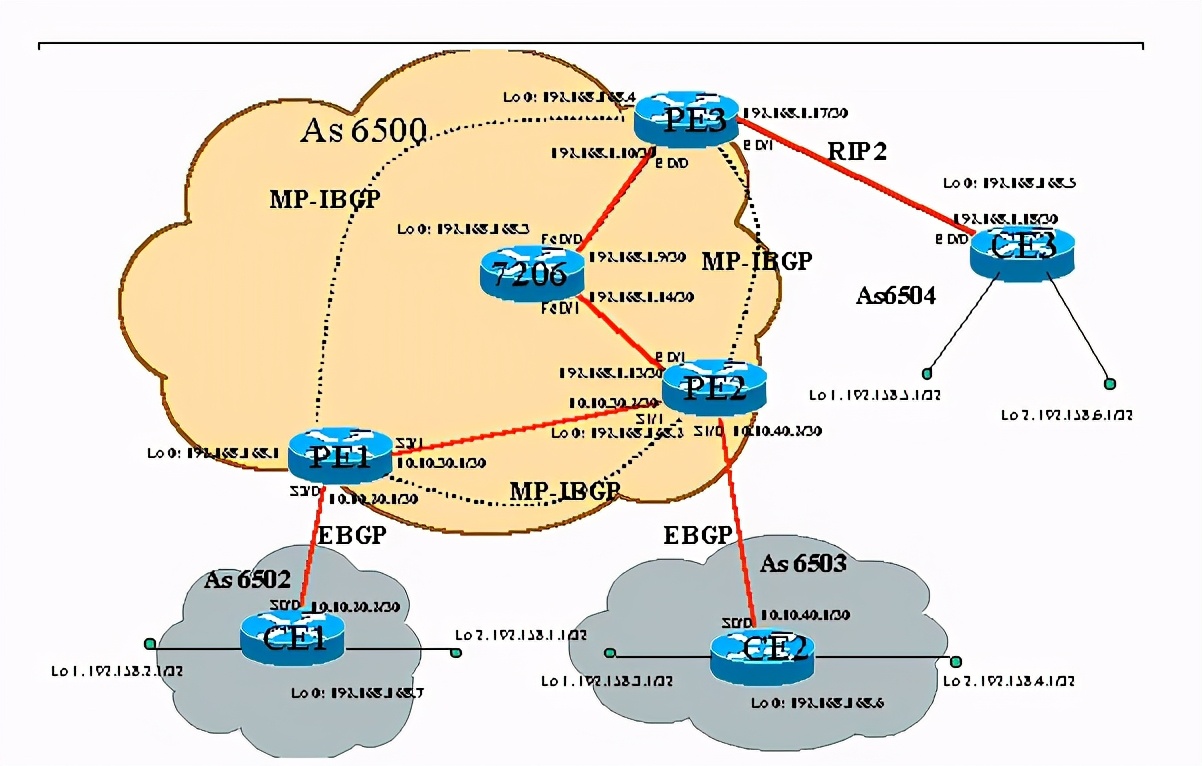
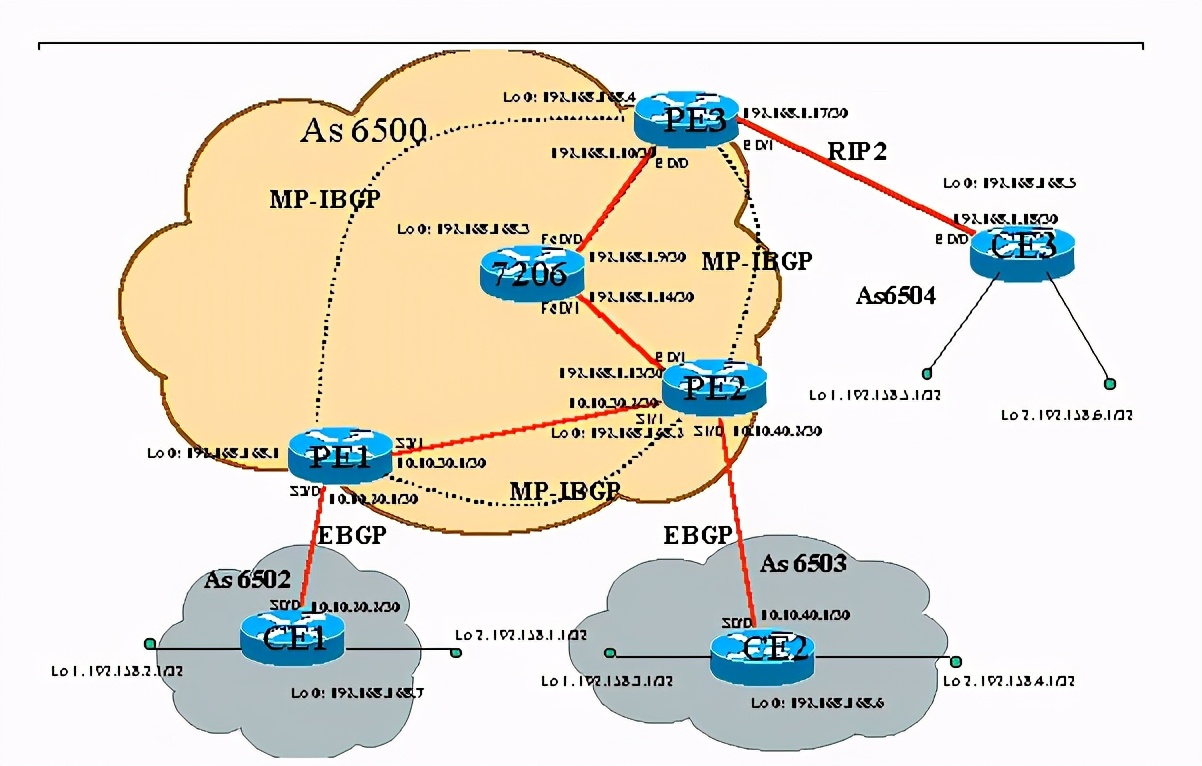
上图中ce1、ce2、ce3组成一个vpn,其中pe3和ce3之间走rip2协议,pe2和ce2之间走bgp协议。整个as 6500中走ospf协议。
pe3的部分配置如下:
ip cef ──启用cef转发功能
ip vrf red ──定义一个 vrf ,名字为red
description for red user vpn
rd 6500:1 ──定义rd值为6500:1
route-target export 6500:1 ──定义导出策略
route-target import 6500:1 ──定义导入策略
router rip ──配置pe3到ce3的路由协议rip2
version 2 !
address-family ipv4 vrf red version 2 redistribute bgp 6500 metric 1──-将bgp学到的路由从新发布的rip2中,network 192.168.1.0 使ce3能学到同一vpn中的其他路由
no auto-summary
exit-address-family
router bgp 6500 ──-配置bgp协议
no synchronization
no bgp default ipv4-unicast
bgp log-neighbor-changes
neighbor 192.168.168.2 remote-as 6500 ──-和pe2建立邻居关系
neighbor 192.168.168.2 update-source loopback0
no auto-summary !
address-family ipv4 vrf red ────为vpn用户配置ipv4地址家族,使
redistribute rip metric 1 vrf red 所管辖的路由表中的路由从新发布到bgp协议中去。
no auto-summary
no synchronization
exit-address-family !
address-family vpnv4 ────具体配置和pe2的关系,使pe3和pe2之间能交换vpnv4路由
neighbor 192.168.168.2 activate
neighbor 192.168.168.2 send-community both
no auto-summary
exit-address-family
interface ethernet0/1 ────-配置连接ce3的接口
ip vrf forwarding red ────-使该接口和前面定义的vrf red联系起来
ip address 192.168.1.17 255.255.255.252
interface ethernet0/0 ──-配置联系到7206上接口
ip address 192.168.1.10 255.255.255.252
half-duplex
tag-switching ip ──-在该接口上启用标签交换 !
pe2上的部分配置如下:
ip cef ──启用cef转发功能
ip vrf red ──定义一个 vrf ,名字为red description for red user vpn
rd 6500:1 ──定义rd值为6500:1
route-target export 6500:1 ──定义导出策略
route-target import 6500:1 ─-定义导入策略
!
同时上传附件router bgp 6500 ─-配制bgp协议
no synchronization
no bgp default ipv4-unicast
bgp log-neighbor-changes
neighbor 192.168.168.4 remote-as 6500
neighbor 192.168.168.4 update-source loopback0
neighbor 192.168.168.4 next-hop-self
──这点在pe-ce之间路由协议为bgp时,一定要配置。
no auto-summary !
address-family ipv4 vrf red
neighbor 10.10.40.1 remote-as 6504 ──配置和ce2之间的路由协议bgp
neighbor 10.10.40.1 activate
no auto-summary
no synchronization
exit-address-family !
address-family vpnv4
neighbor 192.168.168.4 activate ──激活和pe3的mp-ibgp邻居关系
neighbor 192.168.168.4 send-community both
no auto-summary
exit-address-family !
interface serial1/0 ──-配置连接到ce2的接口
ip vrf forwarding red ──把该接口和vrf red联系起来
ip address 10.10.40.2 255.255.255.252
interface ethernet0/1 ──配置连接到7206的接口
ip address 192.168.1.13 255.255.255.252
half-duplex
tag-switching ip ──在此接口上启用标签交换
interface serial1/1 ──-配置连接到pe1的接口
bandwidth 1544
ip address 10.10.30.2 255.255.255.252
encapsulation ppp
tag-switching ip ──在此接口上启用mpls交换
5 总结
上面的配置展现了在单个as内部实现vpn的配置,当然vpn用户的各个接入点往往是地域跨度很大的,所以经常要涉及到跨as提供vpn业务的需求。这样的配置会更加复杂,而且需要各个电信运营商配合行动才行,这里就不在具体展开叙述了。
mpls是一种结合了链路层和ip层优势的新技术。在mpls网络上不仅仅能提供vpn业务,也能够开展qos、te、组播等等的业务。
目前中国网通已经在大规模地在提供基于mpls技术的vpn业务,其他运营商,如中国电信等也在迎头赶上。很快地,就象www技术一样,mpls技术将会影响我们生活的方方面面!